MambaOut 论文阅读笔记
1 手写笔记转换(文字版)
1.1 Mamba 简介
1 | |
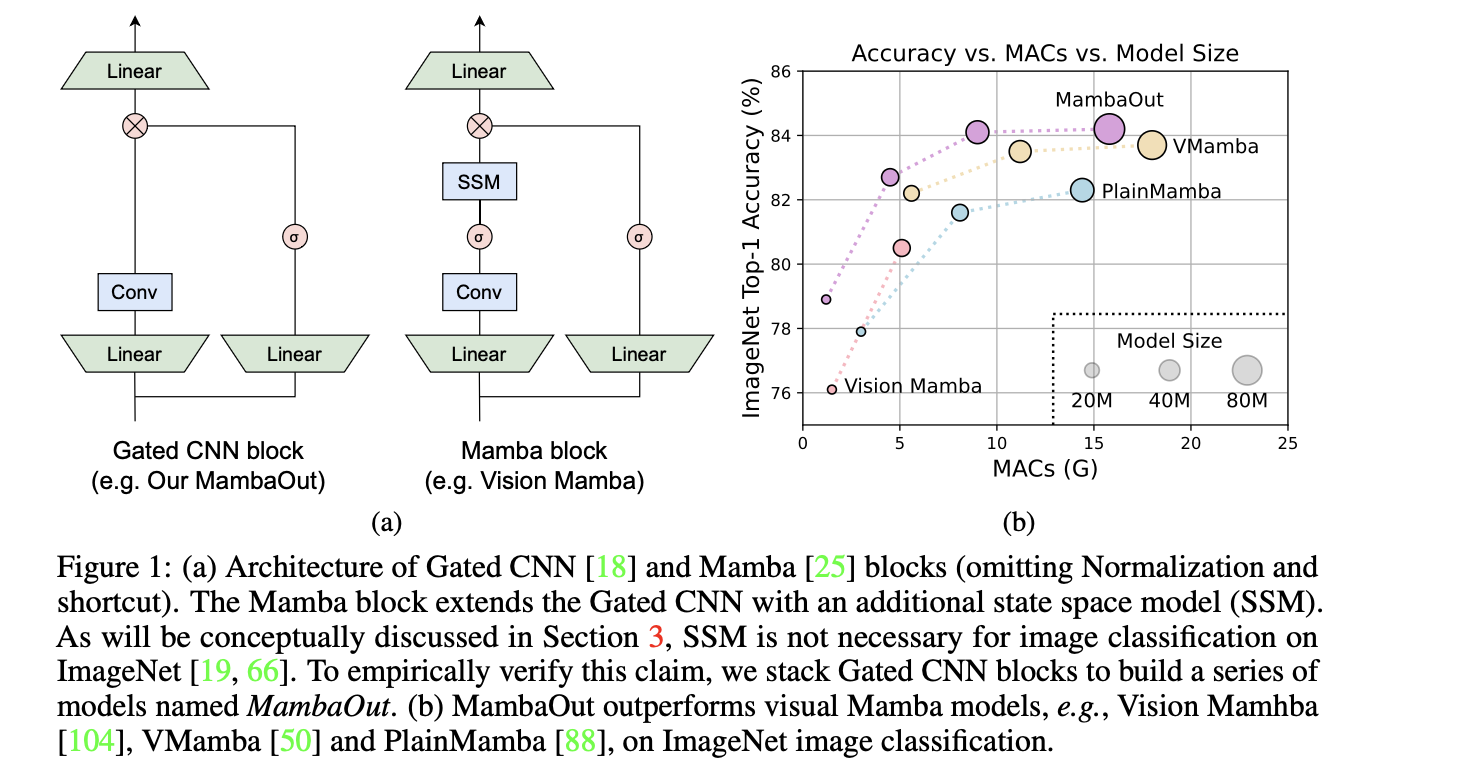
1.2 MambaOut (CVPR 2025)
结论:Mamba 适用于 长序列 和 自回归 任务
因此:对于图像分类效果不好,目标检测和语义分割不算自回归但符合长序列 —— 可能有潜力
自回归:要求每个 token 只从之前和当前的token聚合信息 → Causal Mode
(生成式模型)因果:只与过去的信息有关(← 如 GPT?)
Dino‑v2 自监督是否是这个思路? (蓝笔注)对于 Transformer
- 可以mask掉未来的注意力变成 causal mode
- ViT这样操作在imagenet分类任务中掉点 (不掉才不对吧?)
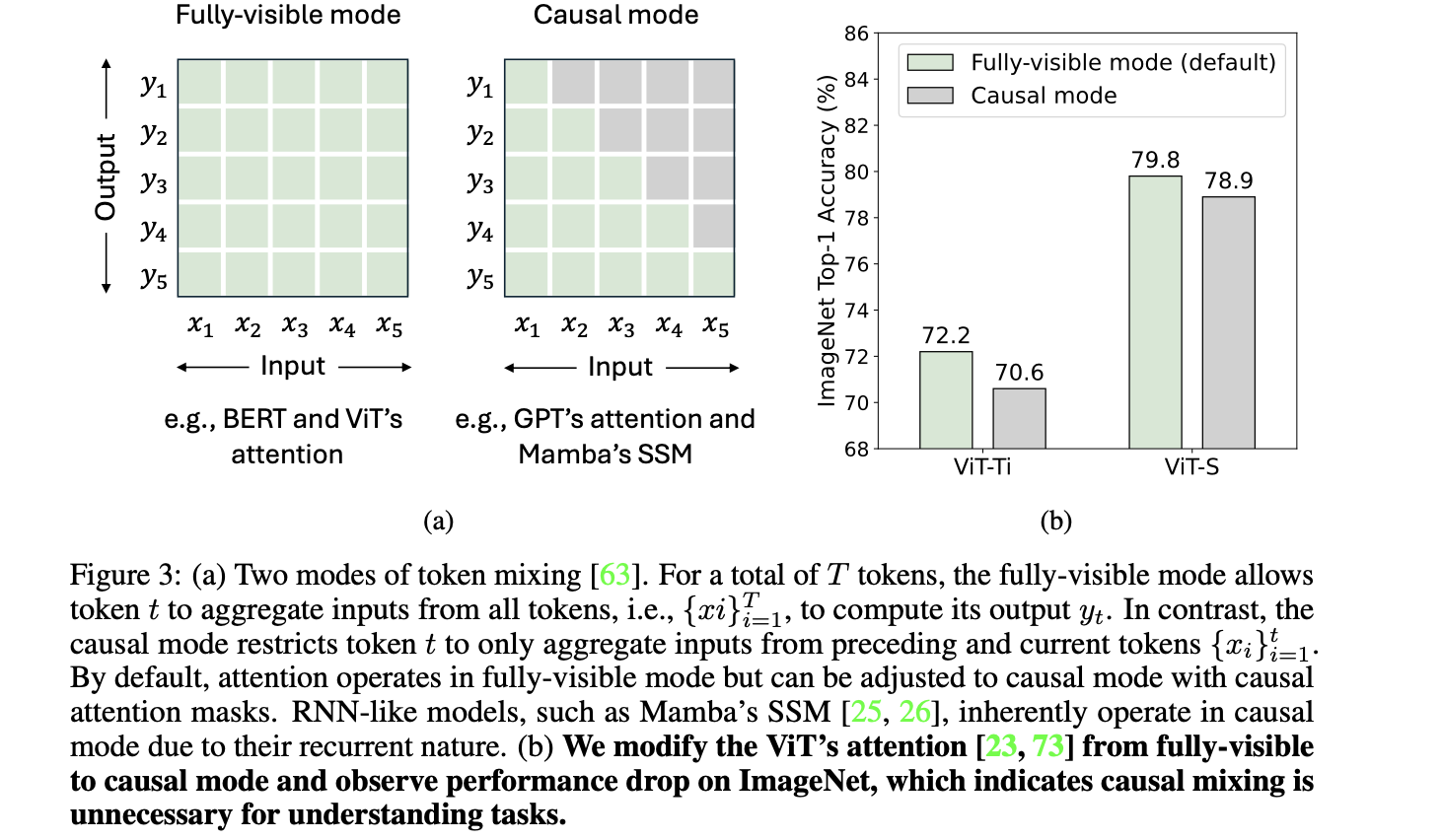
1.3 Mamba Token Mixing
Input dependent parameters 输入相关参数
SSM 的序列‑到‑序列变换 Sequence to Sequence transformation of SSM can be expressed by
隐状态更新 (Hidden state update):
输出 (Output):
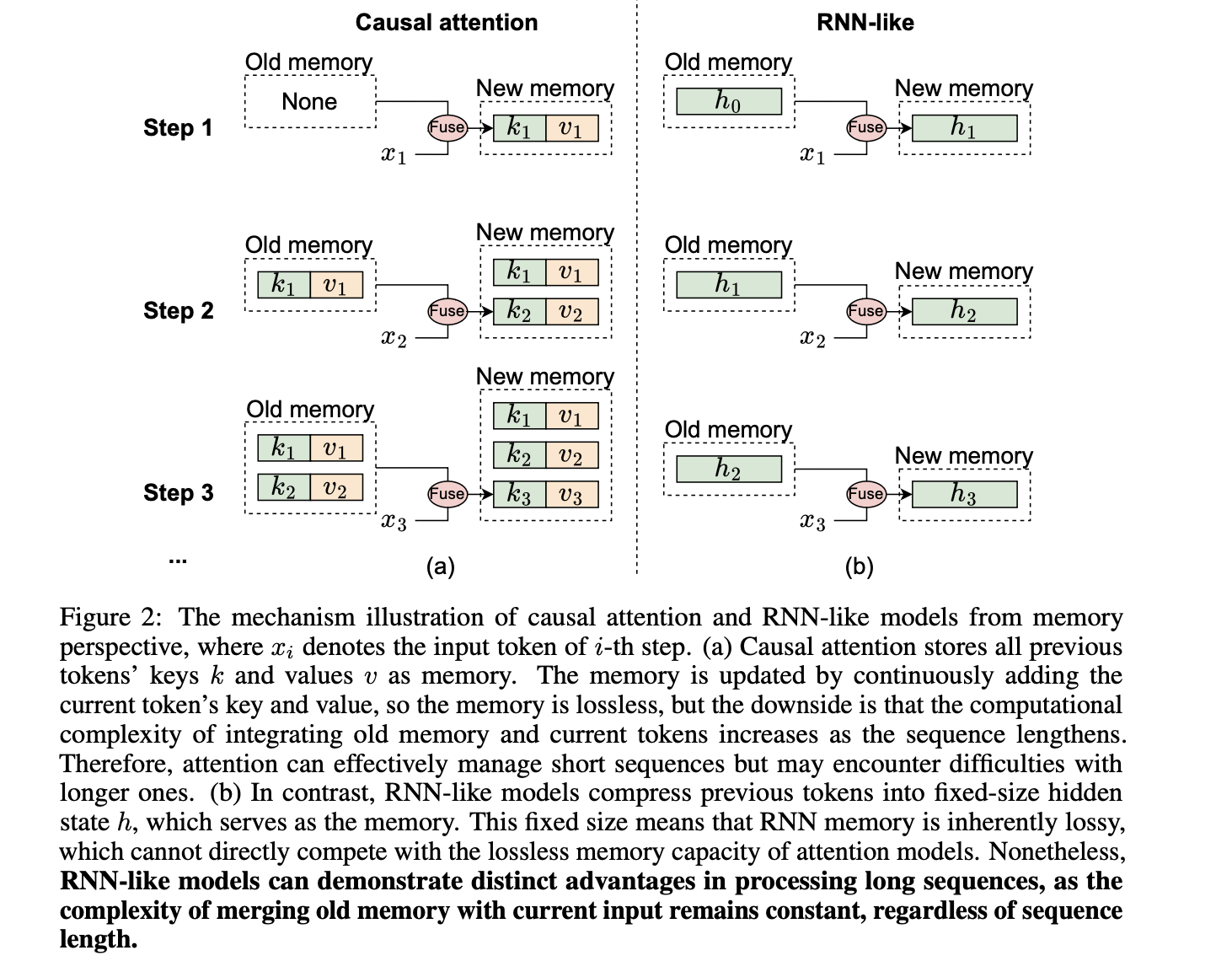
- 隐状态存储了所有历史信息,大小恒定,-> 意味着一定 lossy 有损
而 attention 近似无损,因此理论上在短序列上性能不如attention,长序列上有优势
Limitation:因果性 → 无法在 fully‑visible mode 使用
对图像处理场景的分析
作者利用 MLP ratio = 4 的 Transformer Block,FLOPs:
设输入 ,token length = L,channel = D
二次项 / 线性项 比例:当 ,L² 项主导计算量 → 视为长序列
阈值示例
- ViT‑S,D = 384 → = 6 × 384 = 2304
- ViT‑B,D = 768 → = 4608
ImageNet 分类
输入 ,16×16 patch ⇒ 14×14 = 196 tokens ≪ 阈值 → 短序列COCO 检测 & ADE20K 分割
- COCO 800×1280
- ADE20K 512×2048
Patch 16×16 ⇒ ≈4 k tokens ≥ 阈值 → 长序列
转换阈值,单纯增大图像尺寸可行吗?
例:640 × 192,40 × 12 = 480;再 ×3 = 1440 tokens,似乎仍不足 (蓝笔思考)但是高分辨率应该算 比如1024 × 320 (蓝笔注)
结论:多数图像理解任务 不需要 causal mode
2 实验验证(MambaOut 论文)
论文:”MambaOut: Do We Really Need Mamba for Vision?” (Yu & Wang, CVPR 2025)
2.1 实验设置
| 任务 | 框架 / 关键超参 |
|---|---|
| ImageNet‑1K 分类 | 输入;AdamW;300 epochs;batch 4096;lr 4e‑3;增强 = RandAug(9/0.5)+Mixup/CutMix+RE;SD 0.6 |
| COCO 检测/实例分割 | Mask R‑CNN 1×;;AdamW 1e‑4;batch 16;FP16 |
| ADE20K 语义分割 | UperNet;160 k iters;AdamW 1e‑4;batch 16;FP16 |
| Backbone (MambaOut) | Gated CNN Blocks(无 SSM); DW‑Conv token mixer;MLP ratio = 8/3 |
2.2 ImageNet‑1K 结果
| 模型 | Param (M) | MAC (G) | Top‑1 (%) |
|---|---|---|---|
| MambaOut‑Femto | 7.3 | 1.2 | 78.9 |
| MambaOut‑Tiny | 26.5 | 4.5 | 82.7 |
| MambaOut‑Small | 48.5 | 9.0 | 84.1 |
| MambaOut‑Base | 84.8 | 15.8 | 84.2 |
| LocalVMamba‑S | 50 | 11.4 | 83.7 |
| VMamba‑S | 44 | 11.2 | 83.5 |
| Vim‑S | 26 | 5.1 | 80.5 |
结论:无论参数规模,MambaOut 均优于视觉 Mamba 系列 → 支持 H1。
2.3 COCO 检测 & 实例分割
| Backbone | AP_b | AP_m |
|---|---|---|
| MambaOut‑Tiny | 45.1 | 41.0 |
| VMamba‑T | 46.5 | 42.1 |
| MambaOut‑Small | 47.4 | 42.7 |
| VMamba‑S | 48.2 | 43.0 |
结论:长序列场景下视觉 Mamba 小幅领先,验证 H2。
2.4 ADE20K 语义分割
| Backbone | mIoU (SS) | mIoU (MS) |
|---|---|---|
| MambaOut‑Tiny | 47.4 | 48.6 |
| LocalVMamba‑T | 47.9 | 49.1 |
| MambaOut‑Small | 49.5 | 50.6 |
| VMamba‑S | 49.5 | 50.5 |
结论:ADE20K 超过 4k tokens,视觉 Mamba 仍具微弱优势。
2.5 附录要点
- 模型规格:Tiny/Small 均采用 (3,4,27,3) blocks;通道分别为 96–576。
- ImageNet 训练细节:Stochastic Depth 高达 0.6;增强包括 Mixup、CutMix、Label Smoothing。
2.6 实验结论
- ImageNet:MambaOut(无 SSM)> 视觉 Mamba → 短序列任务无需引入 SSM。
- COCO / ADE20K:视觉 Mamba 在 4k+ tokens 长序列中仍占优。
- 后续方向:Conv+SSM hybrid、多尺度 token mixing、双向 SSM 等值得探索。
End of notes.