在macbook上运行大语言模型第二集:使用chatglm.cpp流畅运行清华chatGLM2-6B大模型
之前一篇介绍了如何在macOS上用cpu运行清华chatGLM大模型,但是也提到模型推理速度非常慢,并不实用。前几天我尝试了llama.cpp项目,效果很惊喜,想起来之前写的运行chatGLM大模型的博客,干脆再写一篇,说说怎么使用chatglm.cpp项目在macOS上流畅运行清华chatGLM2-6B大模型,在cpu上实现比较流畅的聊天体验。chatglm.cpp这个项目实际上脱胎于llama.cpp,这篇写chatglm.cpp主要是为了和上一篇做一个比较直接的速度上的对比,后面可能也会写一篇在mac上运行llama.cpp的博客。
首先上项目地址:https://github.com/li-plus/chatglm.cpp
下载编译chatGLM.cpp项目
首先clone项目到本地:git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp
使用cmake编译:cmake -B build && cmake --build build -j --config Release
Apple Silicon 用户可以开启Metal支持,这样可以使用GPU进行推理,速度会快很多:cmake -B build -DGGML_METAL=ON && cmake --build build -j
准备chatGLM2-6B模型
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q8_0 -o chatglm2-ggml.bin
这时会自动下载chatglm2-6b模型,下载完成后会自动转换模型,进行8位量化,完成后会在当前目录下生成chatglm2-ggml.bin文件。注意这个过程需要把整个模型加载到内存里,内存占用很大,我16G内存的mbp在运行的时候出现了内存不够用进程被kill的情况,关掉了其他的一些应用才成功运行。
这里可选的模型包括:
- ChatGLM-6B: THUDM/chatglm-6b, THUDM/chatglm-6b-int8, THUDM/chatglm-6b-int4
- ChatGLM2-6B: THUDM/chatglm2-6b, THUDM/chatglm2-6b-int4
- CodeGeeX2: THUDM/codegeex2-6b, THUDM/codegeex2-6b-int4
- Baichuan-13B: baichuan-inc/Baichuan-13B-Chat
- Baichuan2-13B: baichuan-inc/Baichuan2-13B-Chat
可选的量化模式包括: - q4_0: 4位整数量化,fp16缩放
- q4_1: 4位整数量化,fp16缩放和最小值
- q5_0: 5位整数量化,fp16缩放
- q5_1: 5位整数量化,fp16缩放和最小值
- q8_0: 8位整数量化,fp16缩放
- f16: 半精度浮点数权重,不进行量化
- f32: 单精度浮点数权重,不进行量化
根据chatGLM.cpp项目说明,对于LoRA模型,可以添加-l <lora_model_name_or_path>flag将LoRA权重合并到基本模型中。
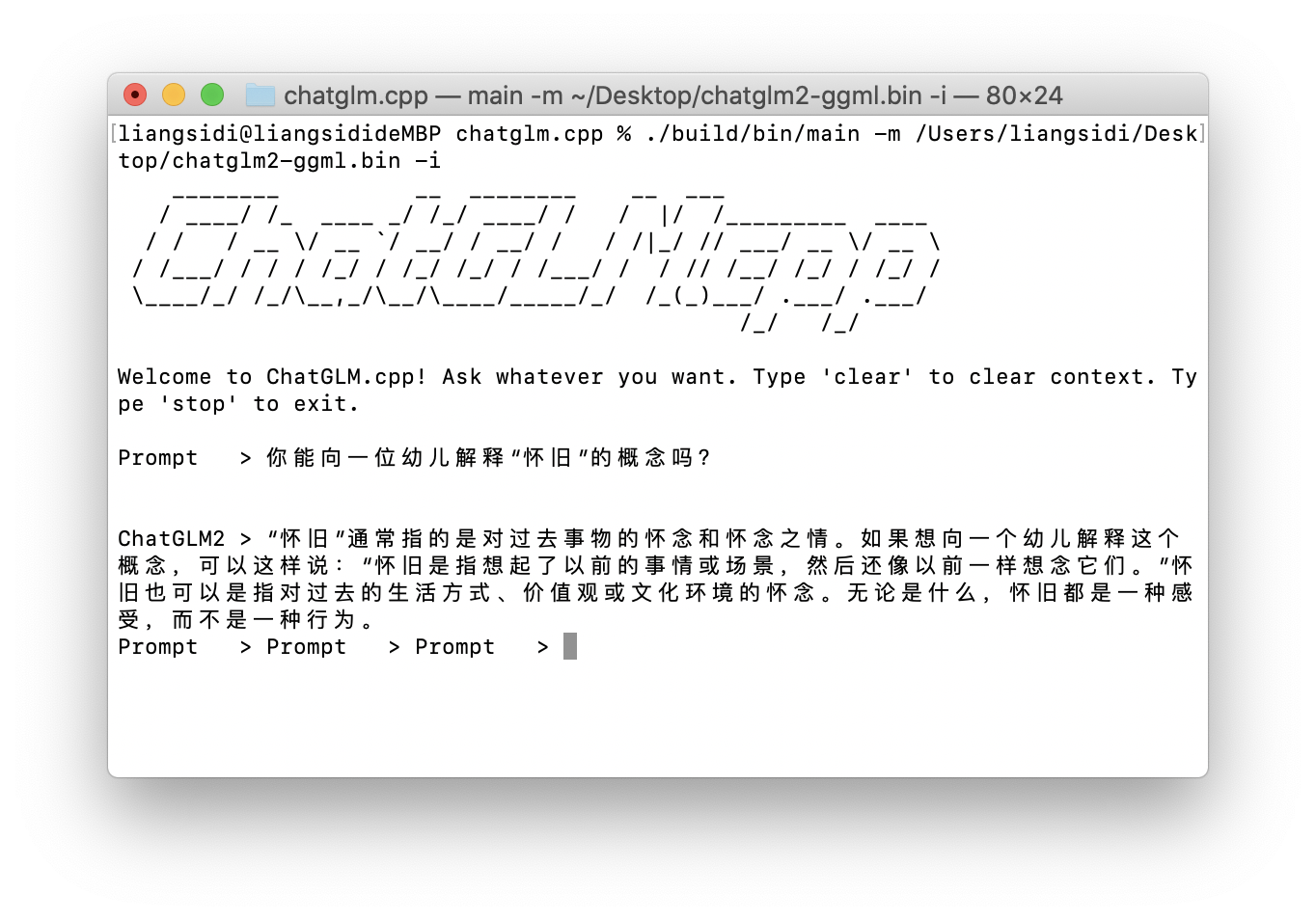
开始聊天!
./build/bin/main -m /Users/liangsidi/Desktop/chatglm2-ggml.bin -i 进入交互模式,开始聊天!可以发现和之前几十秒蹦出来一个单词比,得益于chatGLM.cpp的高效实现以及模型量化,这个模型的推理速度非常快,仅用CPU也可以接近网页版chatGPT的生成速度(当然模型的规模比chatGPT小太多了)。内存占用也很低,只有几百M,可以说达到了实用水平。这下在mac上运行大模型终于不是标题党了!