在mac上用cpu运行清华chatGLM-6B大模型,拥有自己的chatGPT!
用mac也可以部署运行大模型!标题其实有些夸大的成分,因为用cpu进行模型推理实在是太慢了,没有什么实际意义,但是也算是一种体验大模型的方式吧。
先上一段官方介绍:
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答.
部署过程
首先把chatGLM的代码clone到本地:
1 | |
然后将chatGLM-6B的权重下载到本地:
1 | |
下载好之后,用pip安装依赖:
1 | |
都安装好之后,需要对代码进行一些修改才能让其在mac上顺利运行。
这次我主要尝试运行cli_demo.py。我这里将其复制为my_cli_demo.py,第6、7行做如下修改:
1 | |
改为
1 | |
如果是M1或者M2的mac,可以改成下面这样来启用GPU推理(前提是安装了PyTorch-Nightly,可参考Apple 官方教程):
1 | |
然后找到chatglm-6b下modeling_chatglm.py, 注释掉1394行至1404行:
1 | |
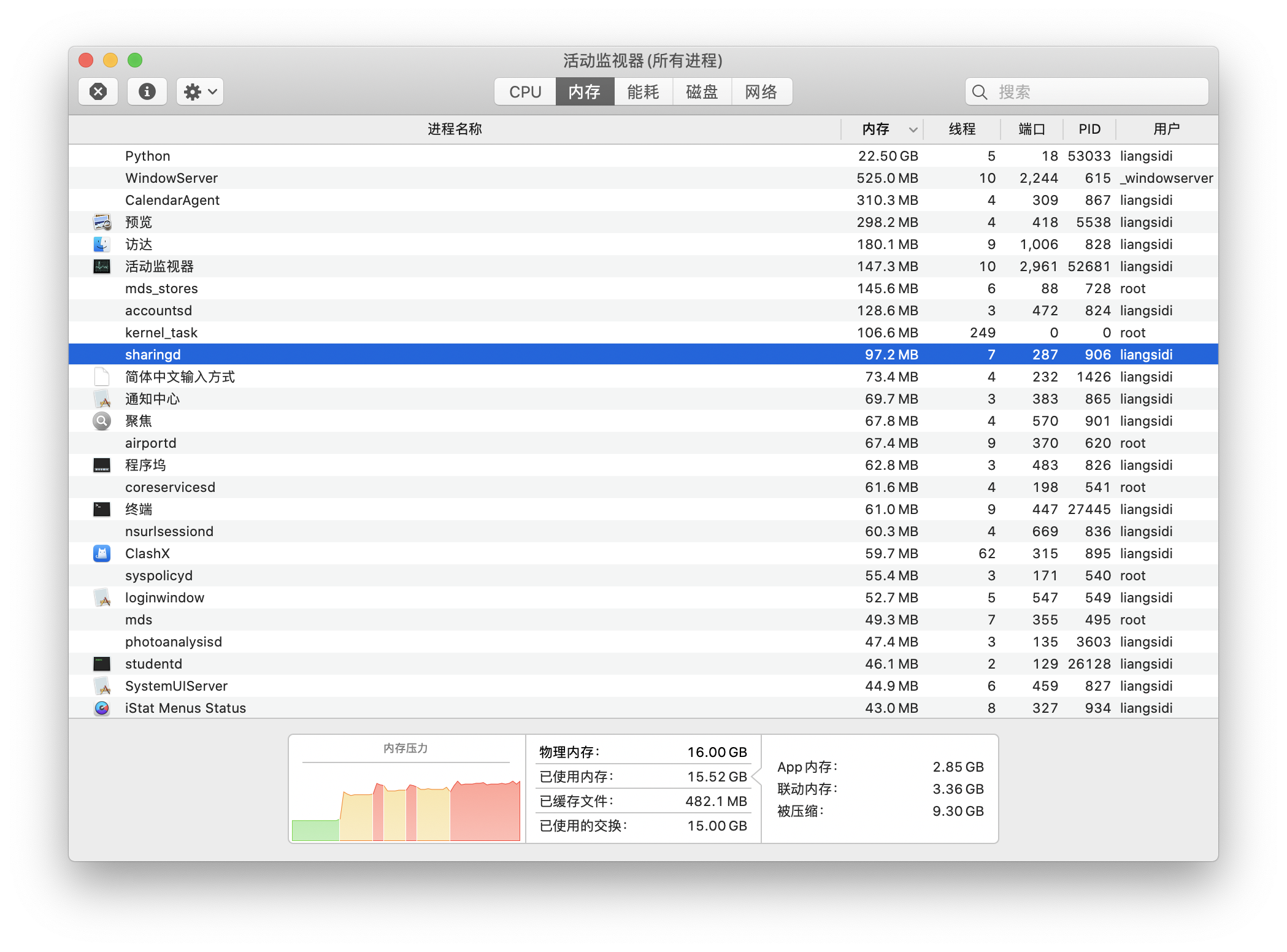
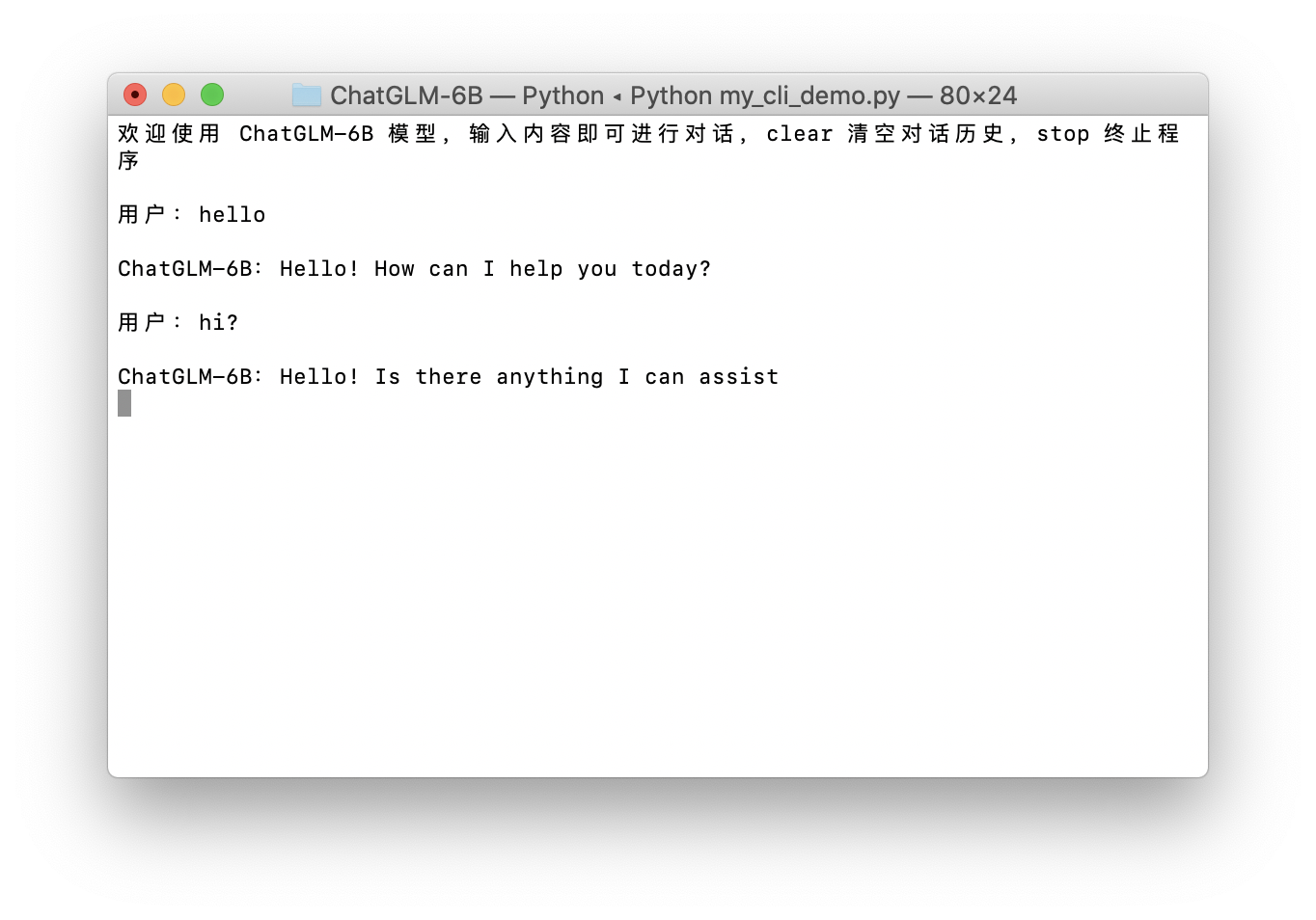
万事俱备!python3 my_cli_demo.py运行!我这里是16GB内存,勉强够用,一个回复大概要等10分钟左右。可能会出现内存不足的情况,可以把其他占内存的应用关掉再试试。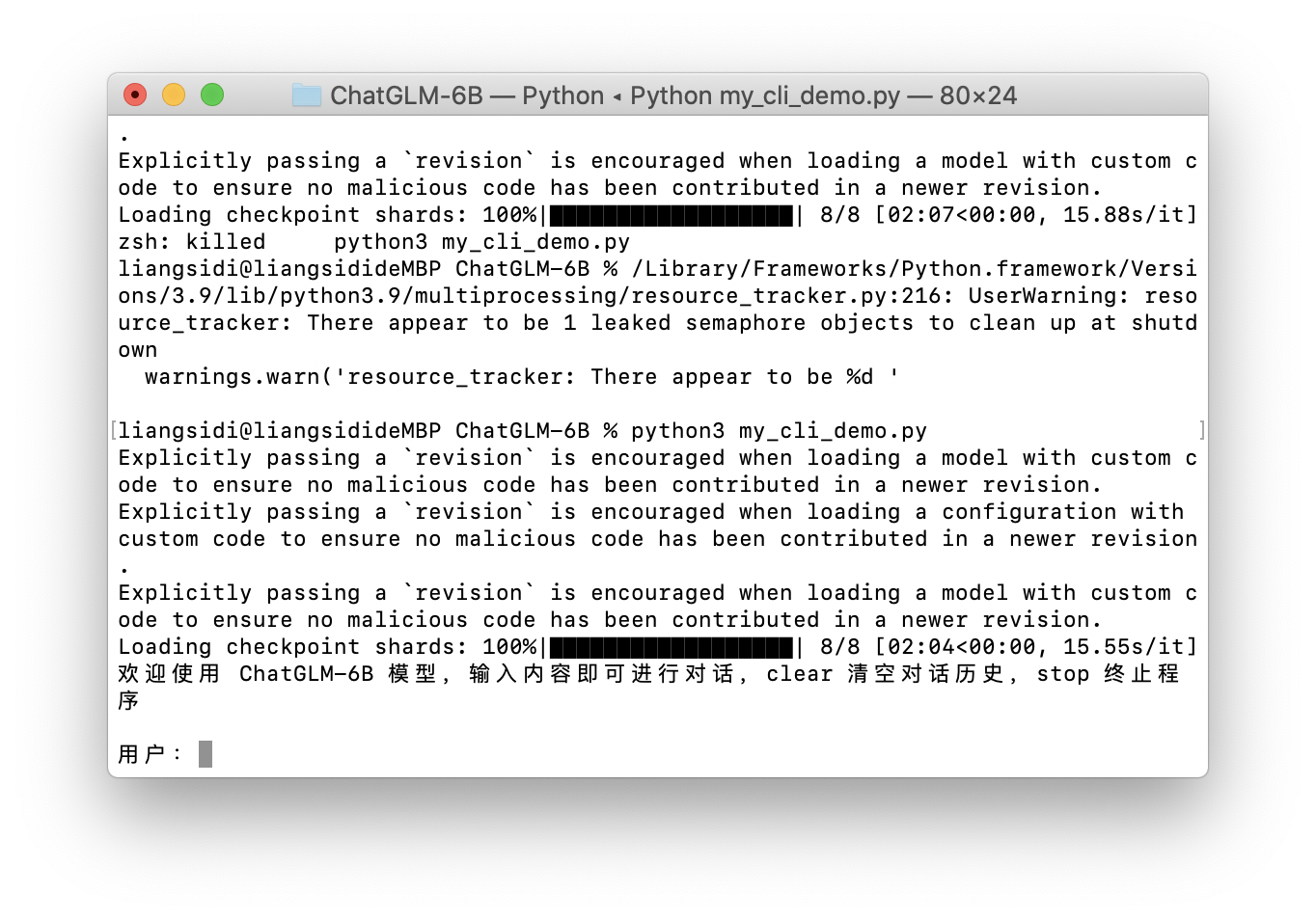
在mac上用cpu运行清华chatGLM-6B大模型,拥有自己的chatGPT!
https://sidiexplore.xyz/2023/04/05/chatglm-mac-cpu/